In the previous post the resolution of a Mandelbrot set fractal was greatly increased by generating it in a vertex shader instead of a fragment shader, because full highp 32 bit floats where available instead of the mediump 16-bit half-floats that many mobile devices limit their fragment shaders to. The mantissa precision increased from 10 bits to 23 bits.


At a scale of 10^(-4) the difference is obvious. Earlier I tried emulating a higher precision in the fragment shader inspired by this blog post, but it just wouldn’t work with the half-floats. It worked beautifully in the Android Emulator when I ran it on my desktop, but my desktop always uses full 32-bit floats even for the mediump fragment shader floats, which we can’t expect in a mobile device fragment shader.
Now when we are doing the calculation in the vertex shader instead we have full 32-bit floats on all mobile devices, just like the Android Emulator, so let’s try this again.
Representing a double with two floats
We’ll split the double up into a high and low part and put them in two floats
vec2 df; df.x = high; df.y = low
Since we’re using complex numbers that already are split up in real and imaginary components we’ll need four floats to represent a double complex number.
vec4 c; c.xy = vec2(hihg_real, low_real); c.zw = vec2(high_imag, low_imag);
We’re now using the full 128 bit vectors that GLSL supports to represent our complex values. We can use the primitive type vec4.
We need methods to split, add and multiply these emulated doubles. See them in this blog post. They will need to be rewritten and optimized for complex numbers. Since GLSL doesn’t have any operator overloading the code ends up looking a bit messy.
attribute vec3 position;
uniform vec4 offset; //vec4(hihg_x, low_x, high_y, low_y)
uniform vec4 scale;
...
vec2 real = add(mul(scale.xy,position.x, offset.xy);
vec2 imag = add(mul(scale.zw,position.y, offset.zw);
vec4 c = vec4(real, imag);
vec4 z = vec4(0.);
...
for(i = 0; z.x*z.x + z.z*z.z < ESCAPE_RADIUS; i++) {
z = add(mul(z,z), c);
}
...
We can’t interpolate the split attributes, but it never happens because there is one vertex per fragment. In fact I should try turning the interpolation off if possible. In the for-loop condition we only use the high parts of the real and imaginary values of z.
The add() and mul() methods are hiding a big number of multiplications. This code is much slower then the previous shaders, but it does greatly increase the precision.


Zooming in until the vertex method looks blocky at the scale of 10^(-7) and switching to the emulated doubles method shows the huge improvement. What we’re looking at is a small corner of the black dot that can be seen in the lower art of the images at the top of this post. Now we can zoom in all the way to a scale of 10^(-14) before we start seeing blocks. Whatever stopped the emulation from working properly in the fragment shader isn’t a problem in the vertex shader. This is working great!
Results
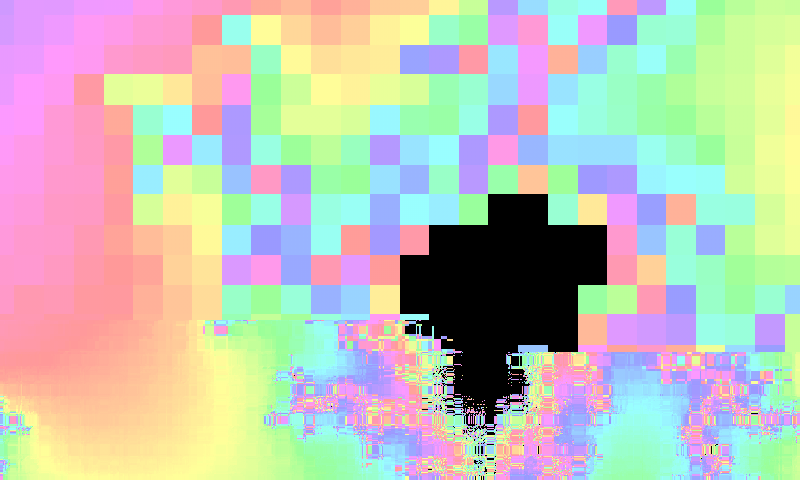
 This is a rendering at the scale of 10^(-13). Occasionally there are some linear discontinuities. I don’t know where these are coming from. Maybe from an incorrect splitting of some doubles. That’s something to look into later.
This is a rendering at the scale of 10^(-13). Occasionally there are some linear discontinuities. I don’t know where these are coming from. Maybe from an incorrect splitting of some doubles. That’s something to look into later.

The shaders are working great in the app!
You can see the full source code on GitHub here. The shaders are in the res/raw folder.